Together with the Water Authority Aa & Maas we have been developing a new algorithm to generate potentially missing culverts.
In the previous blog we discussed how to get to a high detail simulation (beyond a billion grid cells). Now that we have this high detail simulation, we also need to enrich it with accurate data. A lot of that data is available via Geo data sources. However, data on culverts (a tube connection between two waterways) is usually only available for the larger waterways that are part of the Water Authority’s registry.
Unfortunately, most culverts that are situated in smaller waterways, e.g. canals and ditches running along roads are unknown or undocumented. Despite the fact that these culverts have a large impact on how the water system behaves. Without culverts, the waterways will just fill up and create local floodings. It is therefore essential to know all culvert locations in order to do a proper simulation. Fortunately, most missing culvert locations can easily be identified using expert knowledge.
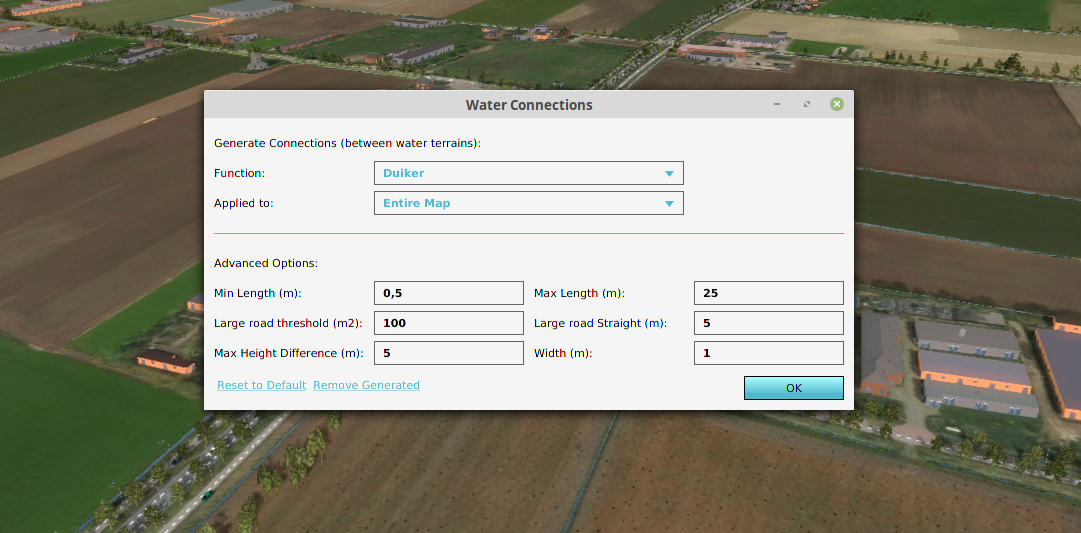
We have been trying to put this expert knowledge into an algorithm that can be used on a large scale, detecting thousands and thousands of previously unknown small culverts. Our strategy is to first detect all potential culvert locations and filter out the locations that are unlikely or outside the parameters. Below is a description of the steps in the algorithm.
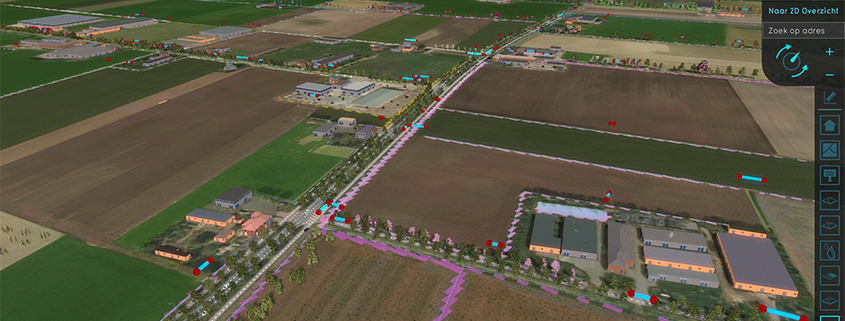
Step 1: We start by calculating the shortest distance between all waterway polygons, ignoring water bodies like lakes and ponds, within an adjustable “Min & Max Length” filter. This can easily be done in parallel and results in a dataset of thousands of lines between all waterway polygons.
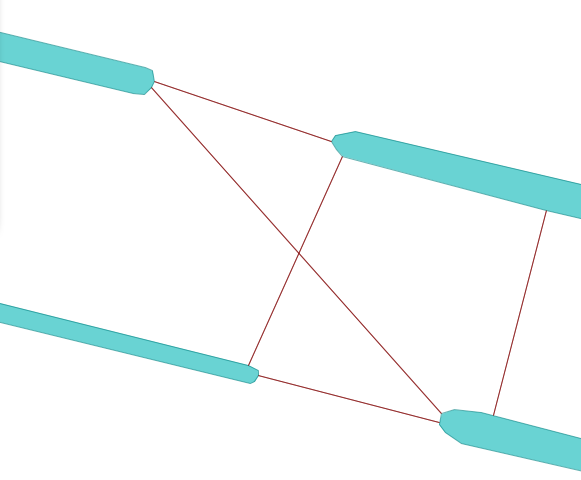
Step 2: After that, we reposition the line so that it is properly within the waterway and not directly on the border. Using a buffer operation the line can also be extended to a polygon with the adjustable “Width” parameter.
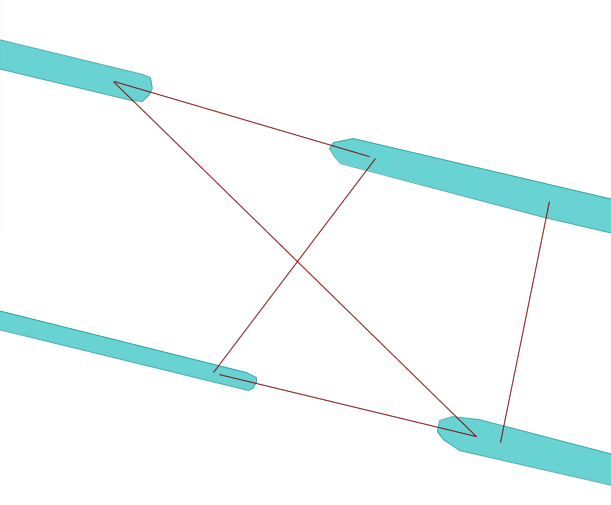
Step 3: When connecting to waterways the space between them may not be occupied by another waterway, water body or building. Using a Quadtree data-structure we can do a fast check whether they are intersecting.
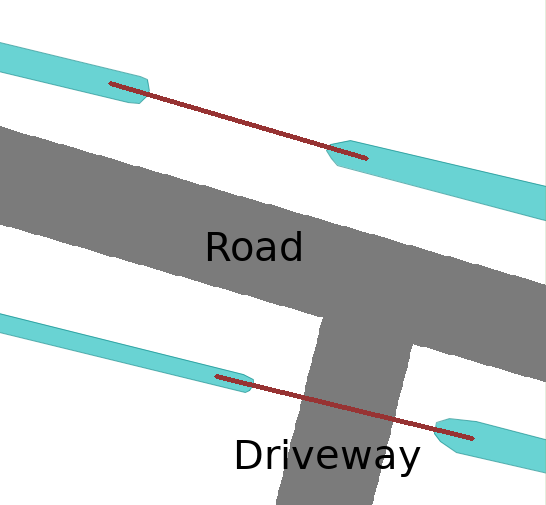
Step 4: The Road rule. A lot of potential culvert connections go beneath roads when there are two waterways on opposite sides of the road. However, only a few result in actual crossings, except for driveways that lead to local farms or houses. Driveways are usually smaller road polygons and therefore all roads smaller then an adjustable “Main Road Area” parameter are accepted. For the remaining larger roads we only accept a connection when the waterway leading up to the crossing is straight for a preset “Straight Distance” parameter. This way, all parallel waterways are ignored and only when the waterway is perpendicular to the road, a connection is accepted.
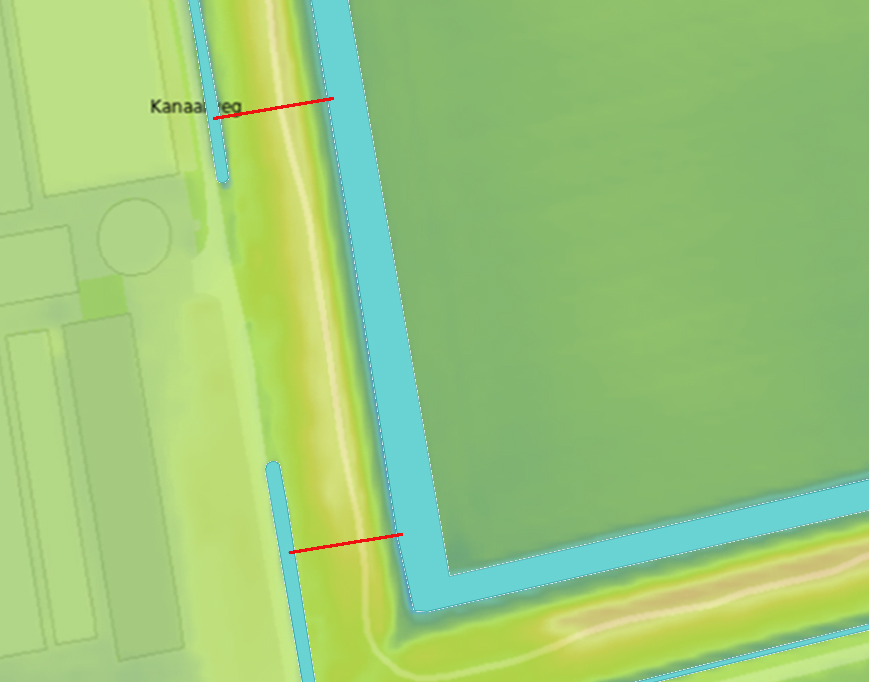
Step 5: The levee rule. A culvert is also not likely to go below a levee. Since this is a potential levee risk, this is usually already part of the known culvert dataset of the Water Authority controlling the levee. To detect a levee one can use the min and max value along the culvert route in the elevation map. When the difference between them is larger then the adjustable “Height Difference” threshold, the connection is ignored.
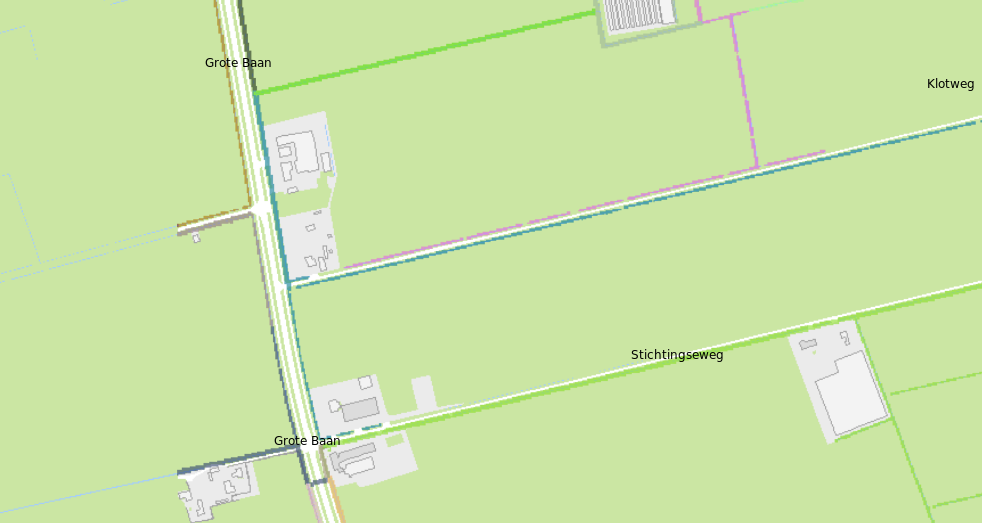
Step 6: Sort on distance. After these five steps, that can fully be done in parallel on the CPU (Tygron Platform has hundreds of CPU Cores) the original dataset of culverts is significantly reduced and will now be sorted on length. We prefer short culvert distances, so they are first.
Step 7: Placements. Starting with the shortest, the culverts are added to the map when there is no existing culvert already in place (e.g. a culvert from the existing Register dataset). Furthermore an existing nearby culvert may not connect the same two waterways (e.g. an identical culvert running in parallel to the generated one). And finally the existing culvert that leads to another waterway may not have the same entry or exit location.
Running these steps generates a new dataset of culverts that can be used in the simulation. They all have a source tag, which allow users to easily remove and rerun the culvert generation process with different parameters. Some areas, for example coastal regions, may have large levees and require a different “Height difference” parameter then a more rural inland area. Fortunately, the generation process can also be applied to sub regions of the project.
Finally this algorithm depends on the availability of certain Geo data sources. For example in the Netherlands we use as data sources: water (BGT and Top10NL), roads (NWB, BGT and Top10NL), buildings(BAG), elevation model (AHN).
To wrap it up, the generation process is not 100% perfect, but better then having no data. And using the parameters in a clever way, you can also focus on a subset of connections that would most likely require a human expert check to validate.
The created algorithm was tested and used for a large scale project of the Water Authority Aa & Maas to calculate watershed areas. In this project of the whole registry area (60 x 60 km), the known culverts were imported. With the water connection generator, approximately 50 000 culverts were generated. Next the watershed module was used to calculate watershed areas. Because the waterways were connected by the (generated) culverts, less fragmented watershed areas were being calculated.
For more information about the water connection generator, see the documentation: https://support.tygron.com/wiki/Water_Connection_Generator. And please let us know if you have any suggestions on how to further improve the algorithm!